


La pregunta típica que surge con la IA local, ¿qué ordenador necesito para usar IA local?
Pero, pero, mucho antes de definir qué ordenador necesitas, hay tres conceptos que vale la pena tener claros antes de tomar ninguna decisión.
Tres tipos de IA según dónde corre
La IA en la nube es la que todos conocemos, ChatGPT, Claude, Gemini. Te conectas por internet, usas su potencia y pagas por suscripción o por tokens. Cualquier ordenador vale porque el trabajo lo hace el servidor de fuera.
La IA local a nivel de sistema es lo que hacen Copilot+ y Apple Intelligence — usa la NPU o la ANE del chip para correr modelos pequeños directamente en tu dispositivo, sin internet, sin latencia, con cierta privacidad en tareas del día a día. Todavía en consolidación, pero esto va a ser una realidad normalizada en åmeses, no en años.
Y después está la IA local personalizada que es otra historia. Requiere RAM, potencia de GPU y algo de curva de aprendizaje. A cambio te da soberanía total, personalización y privacidad real. Tus datos no salen de tu máquina. Nunca. O solo si lo consideras o cuando lo consideras. Sin talibanismos. O sí, ahí cada uno.
Dos arquitecturas de hardware
La arquitectura tradicional X86 tiene RAM y VRAM separadas, la tarjeta gráfica tiene su propia memoria y hay que rellenarla desde la RAM del ordenador. El cuello de botella es evidente.
La memoria integrada, que es lo que usan Strix Halo, Apple Silicon y el GB10 de Nvidia Spark, comparte una memoria unificada entre CPU y GPU sin ese viaje de datos. Es la arquitectura que se está imponiendo para IA local y tiene mucho sentido.
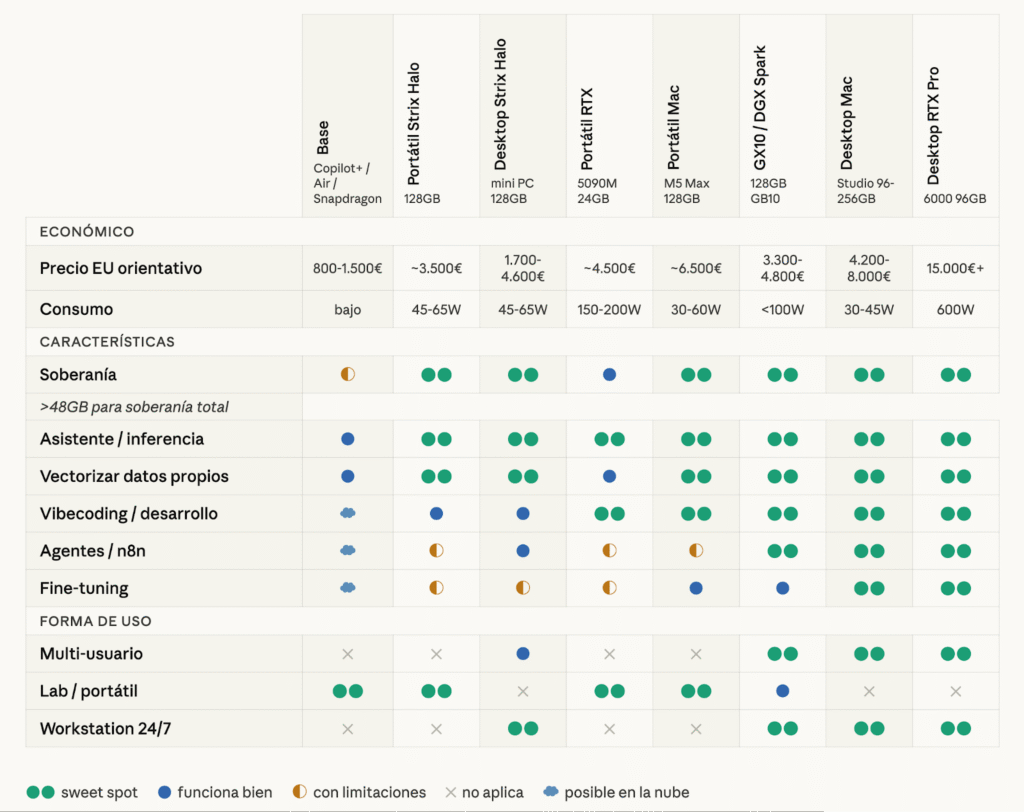
En el cuadro adjunto, puedes encontrar distintas propuestas de hardware y distintos casos de uso que te pueden ayudar hacia donde ir o que buscar. Por supuesto el tipo de ordenador que usas habitualmente también debe pesar en la decisión. Cambiar de ordenador genera una fricción que no es para todos ni tampoco para cualquier momento de vida, no es coña, es realidad aprendida de primera mano.
Cómo funcionan los modelos de Inteligencia Artificial
Hay varios factores combinados que determinan si un modelo local cabe en una máquina y qué puedes esperar de él.
- El tamaño del modelo expresado en billones (ojo aqui q son billions americanos, es decir miles de millones europeos) de parámetros.
- La cuantización, u optimización matemática con cierta reducción de su precisión, aunque menor de lo que imaginamos. (16, 8, 4 bits… y el tipo de optimización que hay varios, int, fp, nv fp4) y por último, si es un …
- modelo denso o un modelo MoE (mixture of experts). Los modelos MoE tienen muchos parámetros en total pero solo activan una fracción en cada inferencia, ahí mucha magia que exprimir.
Llevo un tiempo trabajando en la calculadora para IA local que compartí recientemente y que combina estos tres factores para ayudar a decidir qué corre en qué hardware. Todavía está en mejora continua pero ya muestra ciertas aproximaciones con las que trabajar. Además he incluido tooltips y un pequeño glosario para contextualizar y ayudar a entender.
El ejemplo que me tiene ocupado estos días

Además de la calculadora, y a raiz de toda la explosión de open/nemo Claw, os adjunto un esquema de lo que estoy montando. Un modelo de IA local MoE de 120B, GPT OSS 120b, corriendo en local 24/7, como cerebro compartido para cuatro casos de uso simultáneos;
- agente Open Claw,
- inferencia directa,
- desbordamiento de Claude Code cuando se me acaben los créditos,
- y como modelo base para mis workflows de n8n local.
Un solo modelo, cuatro usos, soberanía total, sin tokens, sin latencia. En breve cuento cómo va en la práctica 😅 Esto es para ir abriedno boca para el próximo.
Por supuesto, si tienes dudas sobre esto de IA local, lo que lo que necesites, y si discrepas, por favor comenta, aprendemos juntos.


